The basics of Distributed Systems

Hiya 👋 I'm Pranav. I'm a recent computer science grad who loves punching keys, napping while coding and lifting weights. This space is a collection of my journey of active learning from blogs, books and papers.
[13]
Introduction
Once upon a time, there was an ice-cream maker named Ben with the most delicious ice-cream in town. His truck was always buzzing with happy customers, but lately, things had gotten a little crazy! The line stretched around the block, and some kids even started getting grumpy waiting for their turn. Ben knew he had to act fast. Hiring more ice-cream trucks seemed like the obvious solution, but there was a problem. It wasn't just about having enough trucks; it was about making sure everyone got served quickly and fairly. Just like a long line wouldn't work, having a bunch of trucks running around wouldn't be efficient either.
Ben needed a smarter way to keep his customers happy. That's when he learned about something called ‘distributed systems.’ Imagine it like this: instead of having just one ice-cream truck, Ben could set up little ice-cream stands all around town. Each stand would have a smaller amount of ice cream, but it would be closer to the kids who wanted it. The cool thing about these stands is that they could all work together. If one stand ran out of chocolate ice cream, it could ask another stand nearby to share. And the best part? Everyone still got served in the same order they arrived, just like in a perfect queue.
That's kind of how distributed systems work in computers too. They're a way of splitting up a big job (like making ice-cream for everyone) into smaller tasks that can be done by lots of different computers (like the ice-cream stands) working together. It's all about making things faster, more efficient, and keeping everyone happy. Okay, that was the ELi5 intro to distributed systems. Now, let's see some technical definition as well.
What exactly are distributed systems?
A distributed system in its most simplest form is a collection of autonomous machines which are physically separated, communicating in order to operate as a single unit. The autonomous computers communicate by sharing resources and files and doing tasks assigned to them. For a system to identify as distributed, it needs to satisfy the three distinct rules (and you can relate it with the ELi5 example I gave above) —
Computers operate concurrently.
Computers fail independently.
Computers do not share a global clock.
The first two are fairly simple to understand but the third one is bit complex topic. Well, let me explain you with an example. Let's say we have a couple of watches and we want to synchronize the time to a unique source of truth. Let's just assume that there’s a certain golden watch which will act as the source of truth or the one which points at the absolute correct time here and we want all the other watches to synchronize with our 'source-of-truth' watch, technically it's impossible to do that due to the current levels of physics limitations that we face everyday.
When make a synchronizing request, we make that request in a certain period of time and there will always be some latency to reach the source of truth and vice versa when getting a response. We can get really, really close to the absolute correct time but we can never get them synchronized together. Hence, we don't want our systems to rely on clocks since they are not reliable in this sense. Of course, there are a couple of standards for dealing with that kind of problems but for now the solution we require is the one that could satisfy the above mentioned requirements.
Distributed systems enables horizontal scaling (read more about scalability here). Remember our overloaded ice-cream truck? In a traditional system (vertical scaling), the only solution would be to supercharge the truck (upgrade hardware). Distributed systems, however, allow us to 'scale horizontally' by adding more ice-cream trucks (more nodes) to handle the growing crowd. Vertical scaling can be effective initially but it has limitations. Even the best hardware can't handle ever-growing workloads or become unwieldy to manage. Horizontal scaling offers an alternative. By adding more computers to the network rather than throwing more power at a single machine, we can distribute the workload and achieve greater capacity. It also gets significantly cheaper after a certain threshold compared to vertical scaling.
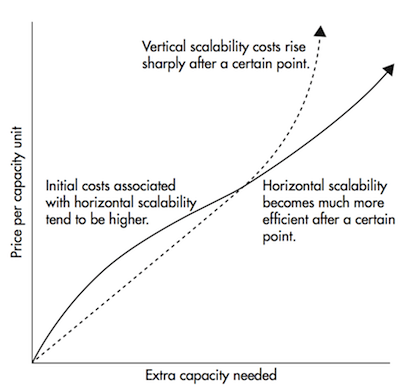
The above image is taken from freeCodeCamp's "A Thorough Introduction to Distributed Systems**"** article which is available here.
Types of Distributed Systems
Distributed systems come in a lot of different models and architectures. Touching three of the well-know architectures below:
The Classic: Client-Server Systems
The early days of distributed systems were dominated by the client-server model. The OG of distributed systems. This architecture revolves around a central server acting as a shared resource, like a database or web server. Clients, such as user workstations, initiate requests and interact with the server for data access, display, modification, and updates. Imagine a library where numerous clients access resources stored in a central server. This approach simplifies management but can become a bottleneck as the number of clients increases.
Peer-to-Peer Networks (P2P)
Early distributed systems leaned on client-server models. However, peer-to-peer (P2P) architectures arose, distributing intelligence and workload across machines. Unlike the centralized approach, P2P has no single leader. Responsibilities are shared, with each machine acting as both client and server. Blockchain exemplifies this — individual nodes collaboratively manage the ledger, eliminating the need for a central server.
Cell Phone Networks
They're advanced distributed systems that share workloads between handsets, switching systems, and internet-based devices.
Decentralized vs/ Distributed
It's important to distinguish between the two terms 'Decentralized' and 'Distributed' because even though they sound the same and can be logically concluded to mean the same thing, there's a huge difference in technology and politics.
Decentralized systems inherit the distributed nature of having components spread across a network (like distributed databases). However, the key differentiator is the lack of a single owner or central authority. A decentralized system wouldn't be decentralized if a single entity controlled it. In addition, Decentralized systems are harder to create because you need to handle the case where some of the participants can be malicious. But, with a distributed system, you own all the nodes, so you don't have to worry about that.
Conclusion
It's safe to say we've barely scratched the surface of distributed systems. I didn't get a chance to discuss the core issues like consensus among independent nodes, implementing robust replication strategies, ensuring consistent event ordering & time synchronization and guaranteeing failure tolerance. This is one of my favorite topics to yap about, so you can definitely expect more posts about it. Peace.




